Power-Ups for Agents: qai is a Direct Replacement for Many MCP Servers

MCP solved a real problem with a protocol layer. For the single-user case it is ceremony. qai is one Go binary with subcommands: no daemons, no schema handshake, no process supervisor. And it adds a primitive MCP cannot: forking your conversation into parallel subagents you can watch.
Power-Ups for Agents: qai is a Direct Replacement for Many MCP Servers
MCP solved a real problem by inventing a protocol for it. When Stripe or GitHub expose tooling to a third-party agent across an organisational trust boundary, you need auth, rate limiting, schema enforcement, versioning and an audit trail. A protocol layer with a server process, a manifest, a handshake and a discovery phase is the correct architectural move for that case. The spec was published, the tooling companies rushed to implement it, and within a year every capability anyone wanted to expose to an agent had an MCP server stapled to it.
And then the ecosystem made a category error. It took the multi-tenant cross-org pattern and started using it for the single-developer case. You can now install an MCP server to let Claude read your local filesystem. An MCP server to run git log on your own repository. An MCP server to tell the time. Each of those is a daemon you now have to start, port-map, manifest, schema-validate and process-supervise. For capabilities that a shell command already exposes on every Unix system shipped since 1973.
qai is a direct replacement for many MCP servers. Not complementary. Not “for certain workflows”. A replacement. It is one Go binary. You install it with a single curl, your agent invokes it as qai <subcommand>, it prints JSON to stdout, and that is the complete architecture. No ports. No daemons. No manifest discovery. No process supervisor catching the filesystem server when it crashes at 2 a.m. and taking your agent down with it. One binary. Subcommands. Exit codes.
Where MCP is still the right answer: anywhere trust crosses an organisational boundary, anywhere a tool needs to enforce a schema against an agent that did not write its own brief, anywhere you are building a marketplace for third-party capabilities. We are not claiming to replace those cases. We are claiming that ninety per cent of the MCP servers currently being installed by individual developers are over-engineering for capabilities already exposed through perfectly good CLIs, and that qai is what those developers should reach for instead.
And, this is the second and larger argument, qai includes a primitive that no MCP server can offer on its own, because it operates on the agent conversation itself rather than on the tools the agent invokes. The ability to fork the parent agent’s live context into parallel subagents you can watch in real time.
The Missing Primitive
Every multi-agent framework in production today treats a subagent as a fresh process with a briefing document. The parent compresses its accumulated understanding into a prompt and ships it. Every delegation is lossy. Ten minutes of careful back-and-forth between a human and a parent agent, establishing what “clean” means in this codebase, which edge cases are tolerable, which teammate’s review comments to defer to, gets flattened into a three-paragraph system prompt before the subagent ever runs. The subagent then does good work on the wrong problem, because the parent could only ship the summary, not the conversation.
We have watched this fail in the same shape across research pipelines, code-review pipelines and content pipelines. A senior agent works with a human for an hour, establishes nuance, then spawns ten worker subagents to parallelise the task. Each worker inherits a faithful rendering of the brief and none of the accumulated correction. One bad assumption in the briefing becomes ten consistent-but-wrong outputs downstream. A code-review agent that had been carefully tuned to ignore a particular false positive spawns a reviewer per file and rediscovers the false positive ten times over. A research agent dispatches three subagents and receives back three documents that duplicate each other’s work, because no subagent could see what the others were reasoning about. The problem is not the agents. The problem is that the framework handed each of them a photocopy of a photocopy.
What the stack is missing is a primitive with a clean name: hierarchical context inheritance with observable parallelism. Both halves carry weight. Hierarchical context inheritance means a child agent starts from the parent’s live conversation, not a serialised digest of it: the subagent knows what the user said at turn three, knows the parent retracted an earlier conclusion at turn nine, knows which files have already been touched, knows the taste judgements the parent and the human arrived at together. Observable parallelism means the parent does not dispatch its children into a black box. It watches them. A human above the parent can watch them too, attach to any one of them, read what they are reasoning about, correct a misreading mid-thought, and let them carry on.
LangChain, AutoGen and CrewAI all offer some version of delegation, and all three collapse at exactly this point. LangChain’s agent-as-tool pattern serialises the parent’s state into a function call argument and returns a string; the subagent is opaque in flight and starts fresh every invocation. AutoGen’s group-chat abstraction keeps multiple agents in a shared message log, but the log is flat (there is no parent whose context any of the participants is forking from) and the human has no live window into any individual agent’s reasoning once the chat starts. CrewAI organises roles cleanly, but again each crew member receives a task description rather than a conversation, and the orchestration happens behind an event loop rather than on a surface a human can attach to. These are competent frameworks solving the wrong problem. The problem they are not solving is the one that matters when real work is at stake: give me a subordinate who already knows what we decided, let me watch them work, let me tap them on the shoulder.
The Tradesman’s Answer
I spent ten years on construction sites before I wrote systems code, and the patterns carry over more directly than people expect. A foreman does not brief the apprentice in the site office and then send them off alone to a locked shed. They hand the job over on the scaffold where the foreman is already standing, with their own eyes on the apprentice’s hands, and they correct the grip before the first nail goes wrong. Same room. Same tools. Same rehearsal. Eyes on the work.
That is what hierarchical context inheritance with observable parallelism actually is, translated from building sites into systems code. It is not a management theory. It is how a crew that does not drop hammers on passers-by behaves in real life. The surprising part is that we already have every primitive needed to build it for agents, and we chose to ignore them because web-app patterns got to our industry first. A subagent running in a terminal pane that the parent can read from and write to is not a research project. It is a straightforward tmux composition. The mistake was treating “I can see what the agent is doing” as optional dashboard chrome rather than as the load-bearing primitive it turns out to be.
qai: the Entry Point
This is the first in a series of posts about what we are calling power-ups for agents: single-purpose composable tools that augment whatever agent you are already using, rather than platforms you have to adopt. The opening move is qai, an MIT-licensed single Go binary that bundles search, code analysis, media generation, browser automation over the Chrome DevTools Protocol, RAG ingestion, a multi-model API gateway, and the subsystem this post is about: tmux-backed agent delegation.
The tmux subsystem is deliberately small. Its whole job is to give any parent agent, Claude or otherwise, the ability to spawn a named terminal pane, send input to it, read what is on screen, and close it when it is done. The surface area fits on a postcard:
qai term spawn research --cwd /work/project
qai term spawn writer --cwd /work/project
qai term spawn redteam --cwd /work/project
qai term send research "gather recent papers on agent observability
and write findings to facts.json; these are the constraints the
parent and I already agreed: no marketing blog posts, no LinkedIn,
English-language sources only, prefer arXiv and primary proceedings."
qai term send writer "when facts.json exists, draft article.md using
the house voice we have been refining in this conversation; do not
include claims not in facts.json."
qai term send redteam "read article.md and flag every sentence that
makes a claim not supported by a specific line in facts.json."
qai term snapshot
qai term read writer --lines 200
qai term send redteam "tighten the review on sections 2 and 4 only;
sections 1 and 3 are already approved by the human."
qai term close researchThree subagents running in parallel, each in its own pane, each inheriting from the parent’s actual conversation because the parent wrote the instructions after the human had been correcting it for an hour. Any human can attach to any pane in Ghostty or iTerm or Terminal.app, read the agent’s live scrollback, type a correction directly to it, and detach. That capability, a human stepping into the middle of a subagent’s work to adjust course, does not exist in LangChain, AutoGen or CrewAI as a first-class surface. In all three, once you have dispatched, you wait. Here, you watch. And if what you watch is going wrong, you talk to the pane.
The MCP Complexity Delta, Side by Side
Back to the claim at the top of this post, made concrete. Here is what it takes to expose a capability to an agent via an MCP server, and what it takes to expose the same capability via qai.
MCP path, single capability:
- Write an MCP server. Choose a language runtime. Ship it.
- Write a manifest declaring the tool’s name, arguments and return schema.
- Configure the agent’s MCP client to discover the server. Register the endpoint.
- At runtime, the agent opens a connection, waits for the server’s
initializeresponse, parses the capabilities list, finds the tool, builds a request that validates against the schema, sends it over the transport, waits for the result, deserialises it. - The server process now runs forever. Something has to supervise it. Port conflicts are possible. Process death is possible. Version drift between the manifest the agent cached and the server you updated is possible.
- Multiply by the number of capabilities you want exposed. Each one is another daemon, another manifest, another supervised process.
qai path, single capability:
qai clip https://example.comThe agent runs a shell command. It gets JSON on stdout. Exit code zero is success, non-zero is failure. There is no server. There is no manifest. There is no handshake. There is no state in between the agent’s invocation and the result. The subcommand returns and the process exits. To add a capability, we add a subcommand to the Go binary. There is no service surface to operate, because there is no service.
This is not a rhetorical trick. Count the moving parts in each path. The MCP version has at least seven. The qai version has one. For third-party multi-tenant exposure, the seven are earning their keep: they buy you auth, schema enforcement, versioning, trust boundaries. For a developer invoking a tool on their own laptop, they are ceremony, and ceremony that the frontier model’s training cut-off date is already making obsolete as every major model vendor ships better CLI-use capability in base inference.
Now the resource argument, which is the one that actually scales. Every MCP server is roughly 60MB of resident memory. A Node.js runtime, a transport layer, a schema validator, a keep-alive connection. Installed and idle. That’s per tool. Ten MCP servers configured on a developer’s machine is roughly 600MB of RAM permanently occupied, whether the agent calls any of them in a given session or not. Thirty MCP servers, which is not an absurd count once a team has filesystem, sqlite, github, time, memory, fetch, playwright, postgres, slack and the rest of the long tail installed, is approaching 2GB. On a laptop. To expose commands that the shell already exposes.
qai does not pay that tax. The binary is ~20MB on disk and zero resident memory when nothing is calling it. The subcommand runs, prints its JSON to stdout, exits, and releases everything. Thirty capabilities exposed through qai is still twenty megabytes on disk and zero resident memory at rest. The cost model is strictly better by several orders of magnitude, and the only reason this is not the default talking point in the MCP discourse is that resource costs look free when you spread them across a cloud budget line and look catastrophic when the developer opens Activity Monitor.
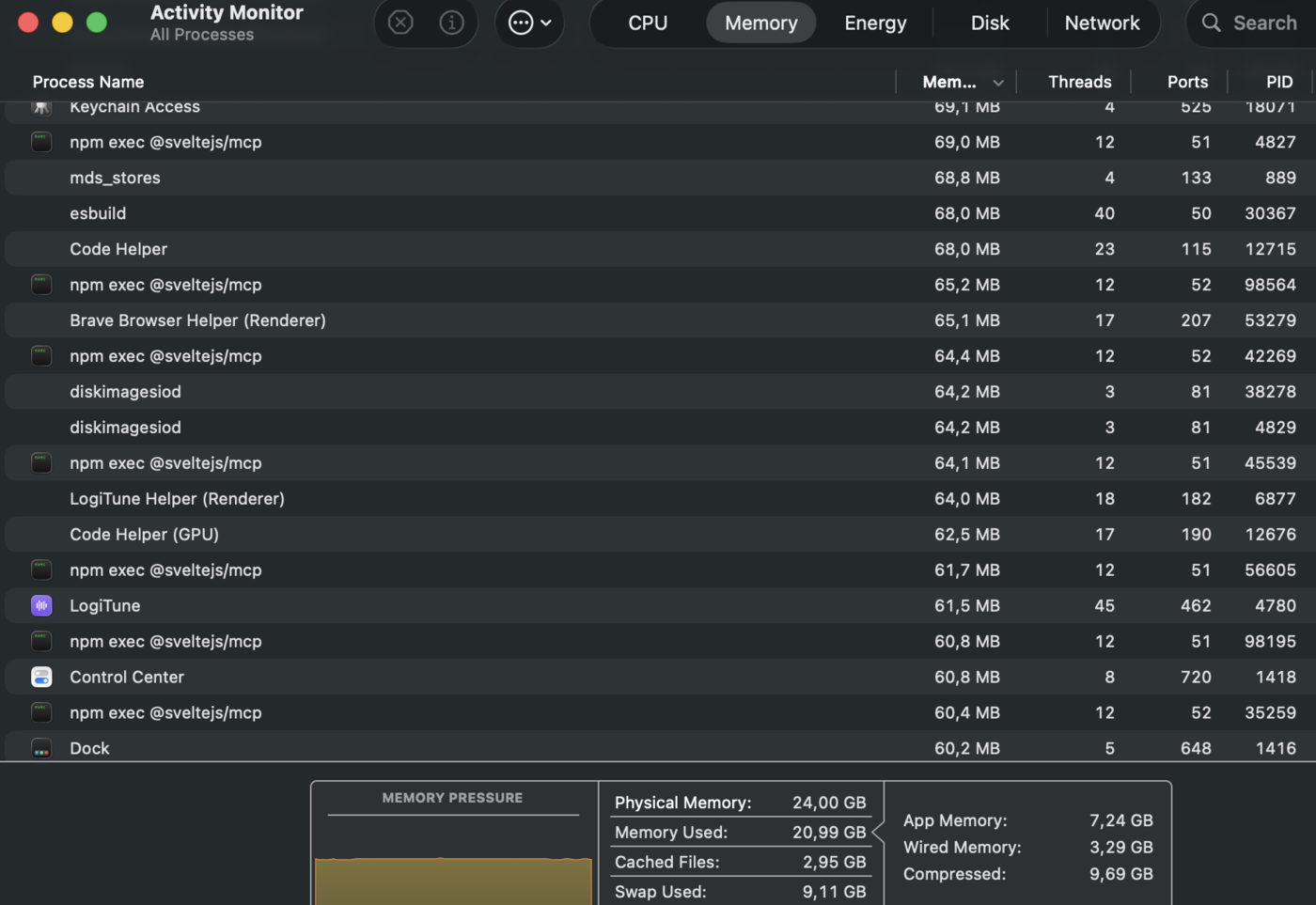
Activity Monitor on a real developer’s machine: seven instances of a single MCP server (npm exec @sveltejs/mcp) occupying roughly 455MB combined, sitting idle. System memory at 87% utilisation, 9.11GB paged to swap. Multiply across every MCP server installed.
There are two details in that screenshot worth naming out loud. The first is that there are seven instances of the same server. MCP’s architecture encourages per-tool server processes, and when parallel agents each want the same tool, you get multiple instances of the same server doing nothing most of the time. That is not a worst-case scenario. That is the ordinary case under the workload every serious agent user is actually running. Six tmux panes each doing qai clip peak at six brief subprocess allocations and return to zero the moment they exit. Six MCP-based agents doing the same thing leave six idle 60MB servers resident afterwards, even if each server was only called once. MCP’s resource model is anti-correlated with parallel-agent workloads, exactly the workload the industry is converging on.
The second detail is the swap line. 9.11GB of memory has been paged to disk because the machine ran out of physical RAM to hold everything resident. Every MB an idle MCP server occupies is a MB the OS could not give to the actual work the agent is doing: the Claude context window, the local embeddings, the RAG vector store, the screenshot buffers, the log tails that agent workflows chew through. Memory pressure cascades into swap pressure, which the user feels as unexplained slowness during long sessions. Activity Monitor is the honest critic of MCP that the protocol’s documentation will never be.
There is exactly one case where the daemon pattern earns its footprint: actual server-style workloads. HTTP in, HTTP out, persistent state, session handling, event streams. If your tool is genuinely a service, if it has to accept concurrent requests, hold sockets open, expire cache entries on a timer, you want a service. But if you are writing a service, you reach for a proper HTTP framework. You do not reach for MCP as an abstraction over what is plainly an HTTP server. Node is the honest default if you already live there. We use Zig because the resource profile matters in the cases we care about, but that is a different post.
There is a design stance underneath this that is worth naming. LLM-ergonomic CLI is a real design discipline, and it is not the same as human-ergonomic CLI. When we design qai subcommands we design for a reader that is a language model. Output shapes are predictable. JSON everywhere the shape is more than a line. No interactive prompts, ever: an agent cannot answer “are you sure? Y/n”. Exit codes that actually mean something, so the agent does not have to parse error strings to know whether to retry. --help output that is legible to a model on first read, not a scroll-through of options grouped by a human’s sense of section aesthetics. Most CLIs were designed for humans at terminals and agents use them anyway, with difficulty and with heuristic parsing. qai is designed for agents from the start and happens to also be fine for humans. That is a strictly better place to land in 2026 than the inverse.
The rest of the qai surface exists to make those panes useful. qai browser drives the user’s real Chrome or Brave over the DevTools Protocol (no headless Chromium, no Playwright, no spoofed user agent) so a research subagent can clip a page through the user’s own authenticated session and save it into Joplin for the next conversation to find. qai analyze and qai scan give a code-review subagent compiler-accurate type information and structural diffs between codebases rather than regex guesses. qai search resolves queries against Joplin, a local SurrealDB RAG and Vertex AI RAG corpora in a single call, so “what did we decide about this last week” is one command away from any pane. None of those are a framework. They are Unix tools that happen to know about modern AI infrastructure.
Two Failure Modes, Built In
The honest version of this post includes the ways context inheritance breaks. We have found two that matter.
The first is that inheritance scales failures as well as successes. If the parent has accumulated a wrong assumption (the user and the parent together concluded that a certain function is safe when it is not) every child forking from that context will confidently repeat the error in ten parallel voices that sound consistent and therefore reassuring. The mitigation has two parts. Before the fork, insert a ground-truth checkpoint: a command, a test run, a document read, something external to the conversation that pins a claim to reality. And compose the crew heterogeneously. Do not spawn N identical workers. Spawn N-1 workers and one adversary whose entire job is to find the places the crew are agreeing because they are wrong, not because they are right. The red-team pane in the example above is not decoration.
The second failure mode is that adversarial review is only useful when the adversary is from a different lineage. Our working pattern for code is Claude-builds, Gemini-red-teams, Claude-fixes, Gemini-verifies: two different model families, two different training distributions, two different error profiles. When the builder and the critic share a parent model they share blind spots; the critic approves the same mistakes the builder introduced. The same shape applies outside code. For a writing task: one family drafts, another audits the draft’s claims against the source material, the first family revises, the second signs off. qai makes this trivial because qai conduct chat is model-agnostic and every pane is free to call whichever model it wants. The framework is not picking the model for you, which means the heterogeneity is yours to compose rather than yours to work around.
Why tmux and Not a Bespoke Dashboard
A custom GUI for multi-agent supervision reinvents ninety per cent of tmux badly. tmux already gives you session persistence across disconnects, SSH-from-your-phone access from anywhere, keyboard-driven pane navigation, scrollback search, copy-paste with a working clipboard, and integration with every terminal emulator anyone has ever shipped. It also gives you a primitive that every agent can target without the framework inventing a new protocol: write text to a pane. A developer writes to a terminal. An agent writes to a terminal. A pane does not care which. If your dashboard cannot be attached from an SSH session on a phone, it is not an observability surface. It is a status page.
Power-Ups, Not Platforms
A platform asks you to adopt it: a runtime, an opinion, a migration, a lock-in. A power-up augments the agent you already have. qai is MIT-licensed, ships as a single Go binary, installs in one line, and speaks to whatever Claude, Gemini, or local model you are already pointing at. It does not replace your agent, it does not rehost your agent, and it does not route your agent’s traffic through anyone’s server. It sits on your machine and makes your agent better at the specific things your agent is bad at today.
curl -sSL https://raw.githubusercontent.com/quantum-encoding/qai/main/install.sh | bashOne line. No account. No cloud dependency for the core. First-time setup is qai init, and from then on every subcommand described above is a normal shell command your parent agent can invoke as naturally as it invokes ls.
What This Is, Actually
Stepping back. Quantum Encoding is building infrastructure that agents use, or could use, written by people who have written systems code on both sides of the AI boundary. qai is the first piece we are publishing because it is the most general-purpose and because it lands on the most important argument we want to make this year: the protocol overhead that got bolted onto the agent-tooling layer was a category error, and the category that matters now is power-ups: small, composable, CLI-shaped augmentations that the agent picks up and uses without ever leaving the shell.
There are other pieces queued behind this one. A Joplin-backed product research pipeline built on qai browser clip and qai search, so an agent can do real research over time rather than rediscovering the web every session. WarpGateway, a cold-boot primitive that takes a fresh VM from nothing to signed-in, trusted and productive without shipping long-lived credentials, which in turn makes the tmux pattern above safe to scale past the local machine. zdedupe, a content-addressed deduplication engine an agent can use as a memory substrate. A Zig PDF engine that is already faster than anything else we have benchmarked. CosmicDuckOS, which is the one you will have to wait for.
We are not going to list all sixteen things we have built. The point is not a catalogue. The point is that if the agent-tooling layer should look like CLIs and not like RPC, and if agent delegation should look like tmux panes and not like invisible task queues, then someone needs to publish a body of work that proves those are not just opinions. That is what we are doing. qai is where it starts.
qai is MIT-licensed and lives at github.com/quantum-encoding/qai.
curl -sSL https://raw.githubusercontent.com/quantum-encoding/qai/main/install.sh | bash